



By Tetiana Stoyko
- CTO & Co-Founder
NoSQL vs SQL databases: How do they differ in development?
Data storage has variations and different approaches to saving and operating the data. How do NoSQL databases differ from SQL?
Clearly, there is probably no more essential thing than a database. In fact, the majority of projects and applications require at least one database for the correct working. Of course, we are talking about databases, used for storing information, related to various working aspects, not the one, that is the storage of different files. However, even data storage itself has variations and different approaches to saving and operating the data. Let’s consider all of them and try to underline the main types of databases, their main features, and working principles.
Main Types: NoSQL vs SQL Databases
Actually, databases are divided into SQL and No SQL types. However, it would be fair to assume, that no SQL is too general a conception, that literally means anything but SQL and can be also divided into subtypes, each of which has its own specifics as well. The reason for such distinction is the fact, that SQL appeared before the development of the most popular no SQL variations and tools, thus staying the main database class for a long time.
What Are Relational Databases
Its name stands for Structured Query Language, and databases of this type are also known as vertical scaling relational model databases. Obviously, these databases are named after the programming language, they are managed with. Alternatively, they are known as relational databases due to their relational model and relational algebra, which all of them rely on. In fact, it is the main feature and advantage of this type, that all data within DB is highly structured and specified. Also, such databases are designed in a specific way as well. For instance, their natural design consists of columns, that contain a determined part of the overall information about various objects and blocks of data.
To sum up, SQL databases are still valuable. First of all, thanks to their structure, they are the best solution in case you are looking for a strict and reliable tool for storing and managing the data, which also won’t cause any issues in working processes or overall understanding of its logic. Also, the long-term usage of such technology not only has proven its trustworthiness but resulted in generating numerous database use cases, solutions, lifehacks, add-ons, and extensions, that can highly improve user experience.
What Are Non-Relational Databases Systems
On the contrary, no SQL databases are a relatively new horizontal scaling approach to storing and managing data. As the name claims, these databases differ from the SQL type. Clearly, the difference lies in the usage of Structured Query Language and relational data model, or to be more precise - not using it. As a result, no SQL databases are not using common query principles and relational data models. Instead, it is possible to say, that they make use of other various data abstractions, which may lead them to be less strict and more chaotic.
Additionally, as was mentioned before, this term is too general. There is no single database type. Instead, it is possible to distinguish at least 4 other subtypes among these databases:
Key-Value Store, which is partly based on association principles. For example, each data entry is provided with a unique key value or a combination of such keys. As a result, all further actions, related to data, are performed with these key values. Therefore, in this case, each data entry is indexed and can be tracked by its key. Sometimes, this type of DBs is compared with dictionaries.
Wide-Column Store, as the name says, this type of no SQL database are storing the data in columns. As a result, it is simple enough to navigate and quickly get the needed part of the information, thanks to its design. In fact, each data entry is divided into various components, each of which is entered in a related column. It is regularly compared with alternative data storage - row-oriented databases. While column DBs store each data entry in a single column, row-oriented ones, obviously, store data in separate rows.
Document-oriented Databases allow storing data as text documents. In fact, this allows the creation of collections. At the first glance, it may seem chaotic and massive, because each such single document store can consist of hundreds and thousands of objects, as well as their description.
Though it may seem tremendously huge at first, data in document-oriented DBs are stored in a format, similar to JSON, which is very easy to read and "user-friendly". In fact, databases such as MongoDB often become a subject of learning in beginner NodeJS courses because of the ease of working with familiar formats and very easy setup. Additionally, it is worth admitting, that sometimes such DBs can be a great solution, capable to deal with an array of data.
Graph DBs are probably the most innovative and interesting example of no SQL databases. In fact, they use nodes and illustrate the relations between these nodes. Additionally, apart from nodes and the relations between them, graph databases represent data in a natural and, therefore, very easy-to-understand format, as many of the already well-known concepts are described as graphs (for example, hierarchies, molecular schemas). Some graph enthusiasts may even say that anything in the world can be represented using 3 graph edges As a result, graph databases simplify some processes, that are more complex in other DB types. For instance, in graph DB it is easier to define and choose elements by their relations, sub relations, etc. Thus, they are a popular choice for Social Network development.
From Development Perspective
In fact, most application developers, who regularly deal with databases, will probably share the opinion, that it is a great idea to combine a few various databases within one project. And yes, it is possible to combine databases and their content in a single project. In this case, we are talking about combining a single SQL and No SQL databases.
As was mentioned before, the SQL database type is a perfect solution, that provides structured and related data storing and managing. Therefore, the developers will be able to better understand the overall logic of an application and will be able to easily operate major information. However, sometimes the SQL DB can be more complex and its “table” abstraction may be overwhelming or result in poor performance or processing power issues. This is why it is better to use it as the main data storage. Yet, we highly recommend choosing an additional no SQL database as a spare option, in order to use it in problematic cases. To better illustrate such cases, let’s consider an example. Let’s suppose we need to get information about the musical albums, that David Gilmour wrote, or took part in their creation. Yet, this singer both performs independently and as a part of a band. Therefore, we have two various data arrays: singer’s albums and band albums. The scheme in the Graphical database Neo4J:
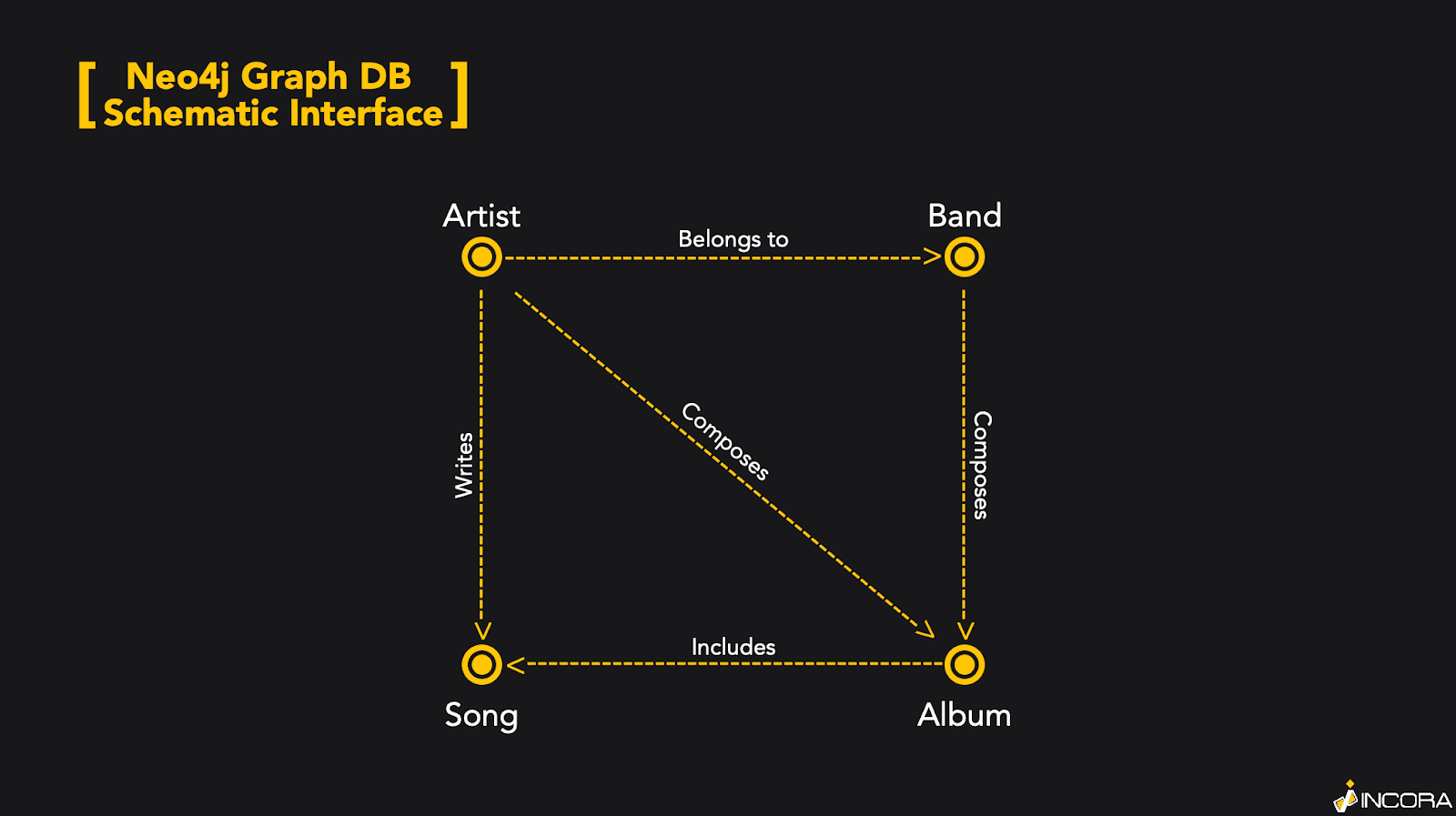
Therefore, there are at least two different paths of how to find the information we are interested in. The first one is to use an SQL database, and the second - is a Graph one. On the code level, the relational database approach to the querying will look like:
SELECT al.*
FROM artists a
INNER JOIN artists_albums aa ON a.id = aa.artists_id
INNER JOIN albums al ON aa.album_id = al.id
WHERE a.name = "David Gilmour"
UNION
SELECT al.*
FROM artists a
LEFT JOIN bands b ON b.id = a.band_id
LEFT JOIN bands_albums ba ON b.id = ba.band_id
INNER JOIN albums al ON aa.album_id = al.id
WHERE a.name = "David Gilmour";
The foregoing code sample will look similar in any other SQL Database. Yet, in the case of a graph database, we have to set up a tech stack, because the code samples may vary, depending on the database and request language used. Let’s suppose that we are using the Neo4j database, combined with the CYPHER query language:
MATCH (artist:Artis {name: "David Gilmour"})
-[:BelongsTo|Releases*1...2] ->(album:Album)
RETURN artist, album;
As we can see, in the case of complex relations, a graph database is much faster and simple to work with. The reason is simple: graph query treats relations as paths, so finding a path is a common graph-theory problem. At the same time, if we consider relational DBs, their relations are bound to other abstractions(table), which is not as good in dealing with paths. Now imagine the scale of coding, if we are talking about even more complex use cases, where paths between elements are much longer.
In one of our recent cases, our developers used such a combination to improve the performance of an app. For instance, we used PostgresSQL as the main database to make the data management more structured and strict, yet in some parts, where SQL data operations were too resource-intensive because there was a wide range of complex queries, we switched to Neo4j graph database in order to improve the performance of a few functions of an app.
Clearly, in such a case, we had to migrate data from the relational database to the graphical one. In fact, there are few ways how to do so. The first and obvious one is to save the data from Postgres as a .csv file, then upload this file into the Neo4j. This specific database is able to read such files and transfer them into the graph format. As a result, each element becomes a node, and each reference or foreign key turns into relations between the objects.
Developers use various APIs, which consider databases as information sources. In fact, most APIs are able to recognize and work with various DBs, but each API will be more useful in specific cases. For instance, REST API can work with all database types, yet won’t use all of their potential and flexibility. In case it is important, GraphQL can easily work with any graphical database, without losing its functionality and characteristics.
Development Differences
Actually, the main differences exist within the capabilities and working processes of databases. Thus, in most cases it doesn’t matter which DB you chose, the tech stack will be changed rarely. In other words, it is correct to say that generally, switching from one DB type to another would require changes only in the “data access” layer of the application. If the application architecture is well-designed, there will be no problems with it.
For instance, you may have to use other APIs, or slightly change some small aspects. Some API styles well complement some databases. As an example, GraphQL would be a great choice over Neo4j DB. Nevertheless, it is worth admitting that you may need the help of developers to deal with some databases due to the fact, that they can be based on various languages i.e. use a different syntax. Yet, these are the major differences, related to the development process.
Summary
Summing up all the above, we can make a few conclusions. First of all, no matter which type of database you choose - it will barely affect the overall development process. Most of the changes and differences lie in a work with the database. Their general logic, database architecture, used syntax, basic programming language, and other similar aspects - are the ones, that differ a lot.
Secondly, when comparing NoSQL vs SQL databases, it is possible to shape main database use cases when it is worth choosing each. For instance, SQL database architecture is a great data management solution, that is strict and vertical data storage. Using such database technology allows for avoiding some possible mistakes and creating a correctly working final product, that will be able to manage data without unneeded actions. Despite the fact, that this database architecture is strict, it is also crystal clear and easy to understand. It is definitely the best choice in the case when data can be well-structured. On the contrary, No SQL database technology is the best possible data management solution in the case, when you will need to deal with sets of unstructured data or data, that is hard to represent as a table. Additionally, sometimes it can help deal with the array of data, as well as an out-of-box approach. It is highly recommended to consider these DBs as a reserve tool, that can be used in various specific cases when SQL databases cannot handle some tasks as effectively.
In fact, the advantage of this DBs type is that there are at least 4 additional subtypes: key-value databases, wide-column stores, document-oriented, and graphical databases. Clearly, all of them have their own strengths and weaknesses, yet it is hard to argue with the fact, that such variety offers a more flexible data model, its storing and management.
FAQ
Let us address your doubts and clarify key points from the article for better understanding.




YOU MAY ALSO LIKE





Get in Touch
Got no clue where to start? Why don’t we discuss your idea?


This site uses cookies to improve your user experience. Read our Privacy Policy
Accept